Функция суммирования в SQL: SUM. Агрегатные функции SQL - SUM, MIN, MAX, AVG, COUNT Построение вычисляемых полей
В этом учебном пособии вы узнаете, как использовать функцию SUM
в SQL Server (Transact-SQL) с синтаксисом и примерами.
Описание
В SQL Server (Transact-SQL) функция SUM возвращает суммарное значение выражения.
Синтаксис
Синтаксис функции SUM в SQL Server (Transact-SQL):
ИЛИ синтаксис функции SUM при группировке результатов по одному или нескольким столбцам:
Параметры или аргументы
expression1
, expression2
, … expression_n
— выражения, которые не включены в функцию SUM и должны быть включены в оператор GROUP BY в конце SQL-предложения.
aggregate_expression
— это столбец или выражение, которое будет суммировано.
tables
— таблицы, из которых вы хотите получить записи. Должна быть хотя бы одна таблица, перечисленная в операторе FROM.
WHERE conditions
— необязательный. Это условия, которые должны выполняться для выбранных записей.
Применение
Функция SUM может использоваться в следующих версиях SQL Server (Transact-SQL):
SQL Server vNext, SQL Server 2016, SQL Server 2015, SQL Server 2014, SQL Server 2012, SQL Server 2008 R2, SQL Server 2008, SQL Server 2005
Пример с одним полем
Рассмотрим некоторые примеры SQL Server функции SUM, чтобы понять, как использовать функцию SUM в SQL Server (Transact-SQL).
Например, вы можете узнать, как общее количество всех products , количество которых больше 10.
В этом примере функции SUM мы выражению SUM(quantity ) установили псевдоним «Total Quantity». При возврате результирующего набора — «Total Quantity» будет отображаться как имя поля.
Пример использования DISTINCT
Вы можете использовать оператор DISTINCT в функции SUM. Например, приведенный ниже оператор SQL возвращает общую сумму salary с уникальными значениями salary , где salary ниже 29 000 долларов в год.
Если бы две salary составляли 24 000 долл. в год, в функции SUM использовалось только одно из этих значений.
Пример использования формулы
Выражение, содержащееся в функции SUM, не обязательно должно быть одним полем. Вы также можете использовать формулу. Например, вы можете рассчитать общую комиссию.
Transact-SQL
SELECT SUM(sales * 0.03) AS "Total Commission" FROM orders;
SELECT SUM (sales * 0.03 ) AS "Total Commission " FROM orders ; |
Пример использования GROUP BY
В некоторых случаях вам потребуется использовать оператор GROUP BY с функцией SUM.
Как узнать количество моделей ПК, выпускаемых тем или иным поставщиком? Как определить среднее значение цены на компьютеры, имеющие одинаковые технические характеристики? На эти и многие другие вопросы, связанные с некоторой статистической информацией, можно получить ответы при помощи итоговых (агрегатных) функций . Стандартом предусмотрены следующие агрегатные функции:
Все эти функции возвращают единственное значение. При этом функции COUNT, MIN и MAX применимы к любым типам данных, в то время как SUM и AVG используются только для числовых полей. Разница между функцией COUNT(*) и COUNT(<имя поля>) состоит в том, что вторая при подсчете не учитывает NULL-значения.
Пример. Найти минимальную и максимальную цену на персональные компьютеры:
Пример. Найти имеющееся в наличии количество компьютеров, выпущенных производителем А:
Пример. Если же нас интересует количество различных моделей, выпускаемых производителем А, то запрос можно сформулировать следующим образом (пользуясь тем фактом, что в таблице Product каждая модель записывается один раз):
Пример. Найти количество имеющихся различных моделей, выпускаемых производителем А. Запрос похож на предыдущий, в котором требовалось определить общее число моделей, выпускаемых производителем А. Здесь же требуется найти число различных моделей в таблице PC (т.е. имеющихся в продаже).
Для того, чтобы при получении статистических показателей использовались только уникальные значения, при аргументе агрегатных функций можно использовать параметр DISTINCT . Другой параметр ALL используется по умолчанию и предполагает подсчет всех возвращаемых значений в столбце. Оператор,
Если же нам требуется получить количество моделей ПК, производимых каждым производителем, то потребуется использовать предложение GROUP BY , синтаксически следующего после предложения WHERE .
Предложение GROUP BY
Предложение GROUP BY используется для определения групп выходных строк, к которым могут применяться агрегатные функции (COUNT, MIN, MAX, AVG и SUM) . Если это предложение отсутствует, и используются агрегатные функции, то все столбцы с именами, упомянутыми в SELECT , должны быть включены в агрегатные функции , и эти функции будут применяться ко всему набору строк, которые удовлетворяют предикату запроса. В противном случае все столбцы списка SELECT, не вошедшие в агрегатные функции, должны быть указаны в предложении GROUP BY . В результате чего все выходные строки запроса разбиваются на группы, характеризуемые одинаковыми комбинациями значений в этих столбцах. После этого к каждой группе будут применены агрегатные функции. Следует иметь в виду, что для GROUP BY все значения NULL трактуются как равные, т.е. при группировке по полю, содержащему NULL-значения, все такие строки попадут в одну группу.Если при наличии предложения GROUP BY , в предложении SELECT отсутствуют агрегатные функции , то запрос просто вернет по одной строке из каждой группы. Эту возможность, наряду с ключевым словом DISTINCT, можно использовать для исключения дубликатов строк в результирующем наборе.
Рассмотрим простой пример:
| SELECT model, COUNT(model) AS Qty_model, AVG(price) AS Avg_price FROM PC GROUP BY model; |
В этом запросе для каждой модели ПК определяется их количество и средняя стоимость. Все строки с одинаковыми значениями model (номер модели) образуют группу, и на выходе SELECT вычисляются количество значений и средние значения цены для каждой группы. Результатом выполнения запроса будет следующая таблица:
| model | Qty_model | Avg_price |
| 1121 | 3 | 850.0 |
| 1232 | 4 | 425.0 |
| 1233 | 3 | 843.33333333333337 |
| 1260 | 1 | 350.0 |
Если бы в SELECT присутствовал столбец с датой, то можно было бы вычислять эти показатели для каждой конкретной даты. Для этого нужно добавить дату в качестве группирующего столбца, и тогда агрегатные функции вычислялись бы для каждой комбинации значений (модель−дата).
Существует несколько определенных правил выполнения агрегатных функций :
- Если в результате выполнения запроса не получено ни одной строки (или не одной строки для данной группы), то исходные данные для вычисления любой из агрегатных функций отсутствуют. В этом случае результатом выполнения функций COUNT будет нуль, а результатом всех других функций - NULL.
- Аргумент агрегатной функции не может сам содержать агрегатные функции (функция от функции). Т.е. в одном запросе нельзя, скажем, получить максимум средних значений.
- Результат выполнения функции COUNT есть целое число (INTEGER). Другие агрегатные функции наследуют типы данных обрабатываемых значений.
- Если при выполнении функции SUM был получен результат, превышающий максимальное значение используемого типа данных, возникает ошибка .
Итак, если запрос не содержит предложения GROUP BY , то агрегатные функции , включенные в предложение SELECT , исполняются над всеми результирующими строками запроса. Если запрос содержит предложение GROUP BY , каждый набор строк, который имеет одинаковые значения столбца или группы столбцов, заданных в предложении GROUP BY , составляет группу, и агрегатные функции выполняются для каждой группы отдельно.
Предложение HAVING
Если предложение WHERE определяет предикат для фильтрации строк, то предложение HAVING применяется после группировки для определения аналогичного предиката, фильтрующего группы по значениям агрегатных функций . Это предложение необходимо для проверки значений, которые получены с помощью агрегатной функции не из отдельных строк источника записей, определенного в предложении FROM , а из групп таких строк . Поэтому такая проверка не может содержаться в предложении WHERE .
ВЫЧИСЛЕНИЯ
Итоговые функции
В выражениях SQL-запросов нередко требуется выполнить предварительную обработку данных. С этой целью используются специальные функции и выражения.
Довольно часто требуется узнать, сколько записей соответствует тому или иному запросу, какова сумма значений некоторого числового столбца, его максимальное, минимальное и среднее значения. Для этого служат так называемые итоговые (статистические, агрегатные) функции. Итоговые функции обрабатывают наборы записей, заданные, например, выражением WHERE. Если их включить в список столбцов, следующий за оператором SELECT, то результатная таблица будет содержать не только столбцы таблицы базы данных, но и значения, вычисленные с помощью этих функций. Далее приведен список итоговых функций .
- COUNT (параметр ) возвращает количество записей, указанных в параметре. Если требуется получить количество всех записей, то в качестве параметра следует указать символ звездочки (*). Если в качестве параметра указать имя столбца, то функция вернет количество записей, в которых этот столбец имеет значения, отличные от NULL. Чтобы узнать, сколько различных значений содержит столбец, перед его именем следует указать ключевое слово DISTINCT. Например:
SELECT COUNT(*) FROM Клиенты;
SELECT COUNT(Сумма_заказа) FROM Клиенты;
SELECT COUNT(DISTINCT Сумма_заказа) FROM Клиенты;
Попытка выполнить следующий запрос приведет к сообщению об ошибке:
SELECT Регион , COUNT(*) FROM Клиенты ;
- SUM (параметр ) возвращает сумму значений указанного в параметре столбца. Параметр может представлять собой и выражение, содержащее имя столбца. Например:
SELECT SUM (Сумма_заказа) FROM Клиенты;
Данное SQL-выражение возвращает таблицу, состоящую из одного столбца и одной записи и содержащую сумму всех определенных значений столбца Сумма_заказа из таблицы Клиенты.
Допустим, что в исходной таблице значения столбца Сумма_заказа выражены в рублях, а нам требуется вычислить общую сумму в долларах. Если текущий обменный курс равен, например, 27,8, то получить требуемый результат можно с помощью выражения:
SELECT SUM (Сумма_заказа*27.8) FROM Клиенты;
- AVG (параметр ) возвращает среднее арифметическое всех значений указанного в параметре столбца. Параметр может представлять собой выражение, содержащее имя столбца. Например:
SELECT AVG (Сумма_заказа) FROM Клиенты;
SELECT AVG (Сумма_заказа*27.8) FROM Клиенты
WHERE Регион <> "Северо_3апад";
- МАХ (параметр ) возвращает максимальное значение в столбце, указанном в параметре. Параметр может также представлять собой выражение, содержащее имя столбца. Например:
SELECT МАХ(Сумма__заказа) FROM Клиенты;
SELECT МАХ(Сумма_заказа*27.8) FROM Клиенты
W HERE Регион <> "Северо_3апад";
- MIN (параметр ) возвращает минимальное значение в столбце, указанном в параметре. Параметр может представлять собой выражение, содержащее имя столбца. Например:
SELECT MIN(Сумма_заказа) FROM Клиенты;
SELECT MIN (Сумма__заказа*27 . 8) FROM Клиенты
W HERE Регион <> "Северо_3апад";
На практике нередко требуется получить итоговую таблицу, содержащую суммарные, усредненные, максимальные и минимальные значения числовых столбцов. Для этого следует использовать группировку (GROUP BY) и итоговые функции.
SELECT Регион, SUM (Сумма_заказа) FROM Клиенты
GROUP BY Регион;
Результатная таблица для данного запроса содержит имена регионов и итоговые (общие) суммы заказов всех клиентов из соответствующих регионов (рис. 5).
Теперь рассмотрим запрос на получение всех итоговых данных по регионам:
SELECT Регион, SUM (Сумма_заказа), AVG (Сумма_заказа), МАХ(Сумма_заказа), MIN (Сумма_заказа)
FROM Клиенты
GROUP BY Регион;
Исходная и результатная таблицы показаны на рис. 8. В примере только Северо-Западный регион представлен в исходной таблице более чем одной записью. Поэтому в результатной таблице для него различные итоговые функции дают различные значения.
Рис. 8. Итоговая таблица сумм заказов по регионам
При использовании итоговых функций в списке столбцов в операторе SELECT заголовки соответствующих им столбцов в результатной таблице имеют вид Expr1001, Expr1002 и т.д. (или что-нибудь аналогичное, в зависимости от реализации SQL). Однако заголовки для значений итоговых функций и других столбцов вы можете задавать по своему усмотрению. Для этого достаточно после столбца в операторе SELECT указать выражение вида:
AS заголовок_столбца
Ключевое слово AS (как) означает, что в результатной таблице соответствующий столбец должен иметь заголовок, указанный после AS. Назначаемый заголовок еще называют псевдонимом. В следующем примере (рис. 9) задаются псевдонимы для всех вычисляемых столбцов:
SELECT Регион,
SUM (Сумма_заказа) AS [Общая сумма заказа],
AVG (Сумма_заказа) AS [Средняя сумма заказа],
МАХ(Сумма_заказа) AS Максимум,
MIN (Сумма_заказа) AS Минимум,
FROM Клиенты
GROUP BY Регион;

Рис. 9. Итоговая таблица сумм заказов по регионам с применением псевдонимов столбца
Псевдонимы, состоящие из нескольких слов, разделенных пробелами, заключаются в квадратные скобки.
Итоговые функции можно использовать в выражениях SELECT и HAVING, но их нельзя применять в выражении WHERE. Oneратор HAVING аналогичен оператору WHERE, но в отличие от WHERE он отбирает записи в группах.
Допустим, требуется определить, в каких регионах более одного клиента. С этой целью можно воспользоваться таким запросом:
SELECT Регион , Count(*)
FROM Клиенты
GROUP BY Регион HAVING COUNT(*) > 1;
Функции обработки значений
При работе с данными часто приходится их обрабатывать (преобразовывать к нужному виду): выделить в строке некоторую подстроку, удалить ведущие и заключительные пробелы, округлить число, вычислить квадратный корень, определить текущее время и т. п. В SQL имеются следующие три типа функций:
- строковые функции;
- числовые функции;
- функции даты-времени.
Строковые функции
Строковые функции принимают в качестве параметра строку и возвращают после ее обработки строку или NULL.
- SUBSTRING (строка FROM начало ) возвращает подстроку, получающуюся из строки, которая указана в качестве параметра строка . Подстрока начинается с символа, порядковый номер которого указан в параметре начало, и имеет длину, указанную в параметре длина. Нумерация символов строки ведется слева направо, начиная с 1. Квадратные скобки здесь указывают лишь на то, что заключенное в них выражение не является обязательным. Если выражение FOR длина не используется, то возвращается подстрока от начало и до конца исходной строки. Значения параметров начало и длина должны выбираться так, чтобы искомая подстрока действительно находилась внутри исходной строки. В противном случае функция SUBSTRING вернет NULL.
Например:
SUBSTRING ("Дорогая Маша!" FROM 9 FOR 4) возвращает "Маша";
SUBSTRING ("Дорогая Маша! " FROM 9) возвращает "Маша! ";
SUBSTRING("Дорогая Маша! " FROM 15) возвращает NULL.
Использовать эту функцию в SQL-выражении можно, например, так:
SELECT * FROM Клиенты
WHERE SUBSTRING(Регион FROM 1 FOR 5) = "Север";
- UPPER (строка ) переводит все символы указанной в параметре строки в верхний регистр.
- LOWER (строка ) переводит все символы указанной в параметре строки в нижний регистр.
- TRIM (LEADING | TRAILING | BOTH ["символ"] FROM строка ) удаляет ведущие (LEADING), заключительные (TRAILING) или те и другие (BOTH) символы из строки. По умолчанию удаляемым символом является пробел (" "), поэтому его можно не указывать. Чаще всего эта функция используется именно для удаления пробелов.
Например:
TRIM (LEADING " " FROM "город Санкт-Петербург") вращает " город Санкт-Петербург ";
TRIM(TRALING " " FROM "город Санкт-Петербург") возвращает "город Санкт-Петербург";
TRIM (BOTH " " FROM " город Санкт-Петербург ") возвращает "город Санкт-Петербург";
TRIM(BOTH FROM " город Санкт-Петербург ") возвращает "город Санкт-Петербург";
TRIM(BOTH "г" FROM "город Санкт-Петербург") возвращает "ород Санкт-Петербур".
Среди этих функций наиболее часто используемые - SUBSTRING() И TRIM().
Числовые функции
Числовые функции в качестве параметра могут принимать данные не только числового типа, но возвращают всегда число или NULL (неопределенное значение).
- POSITION (целеваяСтрока IN строка ) ищет вхождение целевой строки в указанную строку. В случае успешного поиска возвращает номер положения ее первого символа, иначе 0. Если целевая строка имеет нулевую длину (например, строка " "), то функция возвращает 1. Если хотя бы один из параметров имеет значение NULL, то возвращается NULL. Нумерация символов строки ведется слева направо, начиная с 1.
Например:
POSITION ("e" IN "Привет всем") возвращает 5;
POSITION ("всeм" IN "Привет всем") возвращает 8;
POSITION (" " Привет всем") возвращает 1;
POSITION("Привет!" IN "Привет всем") возвращает 0.
В таблице Клиенты (см. рис. 1) столбец Адрес содержит, кроме названия города, почтовый индекс, название улицы и другие данные. Возможно, вам потребуется выбрать записи о клиентах, проживающих в определенном городе. Так, если требуется выбрать записи, относящиеся к клиентам, проживающим в Санкт-Петербурге, то можно воспользоваться следующим выражением SQL-запроса:
SELECT * FROM Клиенты
WHERE POSITION (" Санкт - Петербург " IN Адрес ) > 0;
Заметим, что этот простой запрос на выборку данных можно сформулировать иначе:
SELECT * FROM Клиенты
WHERE Адрес LIKE " %Петербург% ";
- EXTRACT (параметр ) извлекает элемент из значения типа дата-время или из интервала. Например:
EXTRACT (MONTH FROM DATE "2005-10-25") возвращает 10.
- CHARACTER_LENGTH (строка ) возвращает количество символов в строке.
Например:
CHARACTER_LENGTH("Привет всем") возвращает 11.
- OCTET_LENGTH (строка ) возвращает количество октетов (байтов) в строке. Каждый символ латиницы или кириллицы представляется одним байтом, а символ китайского алфавита двумя байтами.
- CARDINALITY (параметр ) принимает в качестве параметра коллекцию элементов и возвращает количество элементов в коллекции (кардинальное число). Коллекция может быть, например, массивом или мультимножеством, содержащим элементы различных типов.
- ABS (число ) возвращает абсолютное значение числа. Например:
ABS (-123) возвращает 123;
ABS (2 - 5) возвращает 3.
- МО D (число1, число2 ) возвращает остаток от целочисленного деления первого числа на второе. Например:
MOD (5, з) возвращает 2;
MOD (2, з) возвращает 0.
- LN (число ) возвращает натуральный логарифм числа.
- ЕХР (число ) возвращает е число (основание натурального логарифма в степени число).
- POWER (число1, число2 ) возвращает число1 число2 (число1 в степени число2).
- SQRT (число ) возвращает квадратный корень из числа.
- FLOOR (число ) возвращает наибольшее целое число, не превышающее заданное параметром (округление в меньшую сторону). Например:
FLOOR (5.123) возвращает 5.0.
- CEIL (число ) или CEILING (число ) возвращает наименьшее целое число, которое не меньше заданного параметром округление в большую сторону). Например:
CEIL (5.123) возвращает 6. 0.
- WIDTH_BUCKET (число1, число2, числоЗ, число4) возвращает целое число в диапазоне между 0 и число4 + 1. Параметры число2 и числоЗ задают числовой отрезок, разделенный на равновеликие интервалы, количество которых задается параметром число 4. Функция определяет номер интервала, в который попадает значение число1. Если число1 находится за пределами заданного диапазона, то функция возвращает 0 или число 4 + 1. Например:
WIDTH_BUCKET(3.14, 0, 9, 5) возвращает 2.
Функции даты-времени
В языке SQL имеются три функции, которые возвращают текущие дату и время.
- CURRENT_DATE возвращает текущую дату (тип DATE).
Например: 2005-06-18.
- CURRENT_TIME (число ) возвращает текущее время (тип TIME). Целочисленный параметр указывает точность представления секунд. Например, при значении 2 секунды будут представлены с точностью до сотых (две цифры в дробной части):
12:39:45.27.
- CURRENT_TIMESTAMP (число ) возвращает дату и время (тип TIMESTAMP). Например, 2005-06-18 12:39:45.27. Целочисленный параметр указывает точность представления секунд.
Обратите внимание, что дата и время, возвращаемые этими функциями, имеют не символьный тип. Если требуется представить их в виде символьных строк, то для этого следует использовать функцию преобразования типа CAST ().
Функции даты-времени обычно применяются в запросах на вставку, обновление и удаление данных. Например, при записи сведений о продажах в специально предусмотренный для этого столбец вносятся текущие дата и время. После подведения итогов за месяц или квартал, данные о продажах за отчетный период можно удалить.
Вычисляемые выражения
Вычисляемые выражения строятся из констант (числовых, строковых, логических), функций, имен полей и данных других типов путем соединения их арифметическими, строковыми, логическими и другими операторами. В свою очередь, выражения могут быть объединены посредством операторов в более сложные (составные) выражения. Для управления порядком вычисления выражений используются круглые скобки.
Логические операторы AND, OR и NOT и функции были рассмотрены ранее.
Арифметические операторы:
- + сложение;
- - вычитание;
- * умножение;
- / деление.
Строковый оператор только один оператор конкатенации или склейки строк (| |). В некоторых реализациях SQL (например, Microsoft Access) вместо (| |) используется символ (+). Оператор конкатенации приписывает вторую строку к концу первой пример, выражение:
"Саша" | | "любит" | | " Машу"
вернет в качестве результата строку " Сашалюбит Машу".
При составлении выражений необходимо следить, чтобы операнды операторов имели допустимые типы. Например, выражение: 123 + "Саша" недопустимо, поскольку арифметический оператор сложения применяется к строковому операнду.
Вычисляемые выражения могут находиться после оператора SELECT, а также в выражениях условий операторов WHERE и HAVI NG .
Рассмотрим несколько примеров.
Пусть таблица Продажи содержит столбцы Тип_товара, Количество и Цена, а нам требуется знать выручку для каждого типа товара. Для этого достаточно в список столбцов после оператора SELECT включить выражение Количество*Цена:
SELECT Тип_товара, Количество, Цена, Количество*Цена AS
Итого FROM Продажи;
Здесь используется ключевое слово AS (как) для задания псевдонима столбца с вычисляемыми данными.
На рис. 10 показаны исходная таблица Продажи и результатная таблица запроса.

Рис. 10. Результат запроса с вычислением выручки по каждому типу товара
Если требуется узнать общую выручку от продажи всех товаров, то достаточно применить следующий запрос:
SELECT SUM (Количество*Цена) FROM Продажи;
Следующий запрос содержит вычисляемые выражения и в списке столбцов, и в условии оператора WHERE. Он выбирает из таблицы продажи те товары, выручка от продажи которых больше 1000:
SELECT Тип_товара, Количество*Цена AS Итого
FROM Продажи
WHERE Количество*Цена > 1000;
Предположим, что требуется получить таблицу, в которой два столбца:
Товар, содержащий тип товара и цену;
Итого, содержащий выручку.
Поскольку предполагается, что в исходной таблице продажи столбец Тип_товара является символьным (тип CHAR), а столбец Цена числовой, то при объединении (склейке) данных из этих столбцов необходимо выполнить приведение числового типа к символьному с помощью функции CAST (). Запрос, выполняющий это задание, выглядит так (рис. 11):
SELECT Тип_товара | | " (Цена: " | | CAST(Цена AS CHAR(5)) | | ")" AS Товар, Количество*Цена AS Итого
FROM Продажи;

Рис. 11. Результат запроса с объединением разнотипных данных в одном столбце
Примечание. В Microsoft Access аналогичный запрос будет иметь следующий вид:
SELECT Тип_товара + " (Цена: " + C Str (Цена) + ")" AS Товар,
Количество*Цена AS Итого
FROM Продажи;
Условные выражения с оператором CASE
В обычных языках программирования имеются операторы условного перехода, которые позволяют управлять вычислительным процессом в зависимости от того, выполняется или нет некоторое условие. В языке SQL таким оператором является CASE (случай, обстоятельство, экземпляр ). В SQL:2003 этот оператор возвращает значение и, следовательно, может использоваться в выражениях. Он имеет две основные формы, которые мы рассмотрим в данном разделе.
Оператор CASE со значениями
Оператор CASE со значениями имеет следующий синтаксис:
CASE проверяемое_значение
WHEN значение1 THEN результат1
WHEN значение2 THEN резулътат2
. . .
WHEN значением N THEN результат N
ELSE результатХ
В случае, когда проверяемое_значение равно значение1 , оператор CASE возвращает значение результат1 , указанное после ключевого слова THEN (то). В противном случае проверяемое_значение сравнивается с значение2 , и если они равны, то возвращается значение результат2. В противном случае проверяемое значение сравнивается со следующим значением, указанным после ключевого слова WHEN (когда) и т. д. Если проверяемое_значение не равно ни одному из таких значений, то возвращается значение результат X , указанное после ключевого слова ELSE (иначе).
Ключевое слово ELSE не является обязательным. Если оно отсутствует и ни одно из значений, подлежащих сравнению, не равно проверяемому значению, то оператор CASE возвращает NULL.
Допустим, на основе таблицы Клиенты (см. рис. 1) требуется получить таблицу, в которой названия регионов заменены их кодовыми номерами. Если в исходной таблице различных регионов не слишком много, то для решения данной задачи удобно воспользоваться запросом с оператором CASE:
SELECT Имя , Адрес ,
CASE Регион
WHEN " Москва " THEN "77"
WHEN "Тверская область" THEN "69"
. . .
ELSE Регион
AS Код региона
FROM Клиенты;
Оператор CASE с условиями поиска
Вторая форма оператора CASE предполагает его использование при поиске в таблице тех записей, которые удовлетворяют определенному условию:
CASE
WHEN условие1 THEN результат1
WHEN уоловие2 THEN результат2
. . .
WHEN условие N THEN результат N
ELSE результатХ
Оператор CASE проверяет, истинно ли условие1 для первой записи в наборе, определенном оператором WHERE, или во всей таблице, если WHERE отсутствует. Если да, то CASE возвращает значение результат1. В противном случае для данной записи проверяется условие2. Если оно истинно, то возвращается значение результат2 и т. д. Если ни одно из условий не выполняется, то возвращается значение результат X , указанное после ключ го слова ELSE.
Ключевое слово ELSE не является обязательным. Если оно отсутствует и ни одно из условий не выполняется, оператор CASE вращает NULL. После того как оператор, содержащий CASE, выполнится для первой записи, происходит переход к следующей записи. Так продолжается до тех пор, пока не будет обработан весь набор записей.
Предположим, в таблице книги (Название, Цена) столбец имеет значение NULL, если соответствующей книги нет в наличии. Следующий запрос возвращает таблицу, в которой вместо NULL отображается текст "Нет в наличии":
SELECT Название,
CASE
WHEN Цена IS NULL THEN " Нет в наличии "
ELSE CAST(Цена AS CHAR(8))
AS Цена
FROM Книги;
Все значения одного и того же столбца должны иметь одинаковые типы. Поэтому в данном запросе используется функция преобразования типов CAST для приведения числовых значений столбца Цена к символьному типу.
Обратите внимание, что вместо первой формы оператора CASE всегда можно использовать вторую:
CASE
WHEN проверяемое_значение = значение1 THEN результат1
WHEN проверяемое_значение = значение2 THEN результат2
. . .
WHEN проверяемое_значение = значение N THEN peзyльтaтN
ELSE резулътатХ
Функции NULLIF и COALESCE
В ряде случаев, особенно в запросах на обновление данных (оператор UPDATE), удобно использовать вместо громоздкого оператора CASE более компактные функции NULLIF () (NULL, если) и COALESCE() (объединять).
Функция NULLIF (значение1, значение2 ) возвращает NULL, если значение первого параметра соответствует значению второго параметра, в случае несоответствия возвращается значение первого параметра без изменений. То есть если равенство значение1 = значение2 выполняется, то функция возвращает NULL, иначе значение значение1.
Данная функция эквивалентна оператору CASE в следующих двух формах:
- CASE значение1
WHEN значение2 THEN NULL
ELSE значение1
- CASE
WHEN значение1 = значение2 THEN NULL
ELSE значение1
Функция COALESCE(значение1, значение2, ... , значение N ) принимает список значений, которые могут быть как определенными, так и неопределенными (NULL). Функция возвращает определенное значение из списка или NULL, если все значения не определены.
Данная функция эквивалентна следующему оператору CASE:
CASE
WHEN значение 1 IS NOT NULL THEN значение 1
WHEN значение 2 IS NOT NULL THEN значение 2
. . .
WHEN значение N IS NOT NULL THEN значение N
ELSE NULL
Предположим, что в таблице Книги (Название, Цена) столбец Цена имеет значение NULL, если соответствующей книги нет в наличии. Следующий запрос возвращает таблицу, в которой вместо NULL отображается текст "Нет в наличии":
SELECT Название, COALESCE (CAST(Цена AS CHAR(8)),
"Нет в наличии") AS Цена
FROM Книги;
Это еще одна часто встречающаяся задача. Основной принцип заключается в накоплении значений одного атрибута (агрегируемого элемента) на основе упорядочения по другому атрибуту или атрибутам (элемент упорядочения), возможно при наличии секций строк, определенных на основе еще одного атрибута или атрибутов (элемент секционирования). В жизни существует много примеров вычисления нарастающих итогов, например вычисление остатков на банковских счетах, отслеживание наличия товаров на складе или текущих цифр продаж и т.п.
До SQL Server 2012 решения, основанные на наборах и используемые для вычисления нарастающих итогов, были исключительно ресурсоемкими. Поэтому люди обычно обращались к итеративным решениями, которые работали небыстро, но в некоторых ситуациях все-таки быстрее, чем решения на основе наборов. Благодаря расширению поддержки оконных функций в SQL Server 2012, нарастающие итоги можно вычислять, используя простой основанный на наборах код, производительность которого намного выше, чем в старых решениях на основе T-SQL - как основанных на наборах, так и итеративных. Я мог бы показать новое решение и перейти к следующему разделу; но чтобы вы по-настоящему поняли масштаб изменений, я опишу старые способы и сравню их производительность с новым подходом. Естественно, вы вправе прочитать только первую часть, описывающую новый подход, и пропустить остальную часть статьи.
Для демонстрации разных решений я воспользуюсь остатками на счетах. Вот код, который создает и наполняет таблицу Transactions небольшим объемом тестовых данных:
SET NOCOUNT ON; USE TSQL2012; IF OBJECT_ID("dbo.Transactions", "U") IS NOT NULL DROP TABLE dbo.Transactions; CREATE TABLE dbo.Transactions (actid INT NOT NULL, -- столбец секционирования tranid INT NOT NULL, -- столбец упорядочения val MONEY NOT NULL, -- мера CONSTRAINT PK_Transactions PRIMARY KEY(actid, tranid)); GO -- небольшой набор тестовых данных INSERT INTO dbo.Transactions(actid, tranid, val) VALUES (1, 1, 4.00), (1, 2, -2.00), (1, 3, 5.00), (1, 4, 2.00), (1, 5, 1.00), (1, 6, 3.00), (1, 7, -4.00), (1, 8, -1.00), (1, 9, -2.00), (1, 10, -3.00), (2, 1, 2.00), (2, 2, 1.00), (2, 3, 5.00), (2, 4, 1.00), (2, 5, -5.00), (2, 6, 4.00), (2, 7, 2.00), (2, 8, -4.00), (2, 9, -5.00), (2, 10, 4.00), (3, 1, -3.00), (3, 2, 3.00), (3, 3, -2.00), (3, 4, 1.00), (3, 5, 4.00), (3, 6, -1.00), (3, 7, 5.00), (3, 8, 3.00), (3, 9, 5.00), (3, 10, -3.00);
Каждая строка таблицы представляет банковскую операцию на счете. Депозиты отмечаются как транзакции с положительным значением в столбце val, а снятие средств - как отрицательное значение транзакции. Наша задача - вычислить остаток на счете в каждый момент времени путем аккумулирования сумм операций в строке val при упорядочении по столбцу tranid, причем это нужно сделать для каждого счета отдельно. Желаемый результат должен выглядеть так:
Для тестирования обоих решений нужен больший объем данных. Это можно сделать с помощью такого запроса:
DECLARE @num_partitions AS INT = 10, @rows_per_partition AS INT = 10000; TRUNCATE TABLE dbo.Transactions; INSERT INTO dbo.Transactions WITH (TABLOCK) (actid, tranid, val) SELECT NP.n, RPP.n, (ABS(CHECKSUM(NEWID())%2)*2-1) * (1 + ABS(CHECKSUM(NEWID())%5)) FROM dbo.GetNums(1, @num_partitions) AS NP CROSS JOIN dbo.GetNums(1, @rows_per_partition) AS RPP;
Можете задать свои входные данные, чтобы изменить число секций (счетов) и строк (транзакций) в секции.
Основанное на наборах решение с использованием оконных функций
Я начну рассказ с решения на основе наборов, в котором используется оконная функция агрегирования SUM. Определение окна здесь довольно наглядно: нужно секционировать окно по actid, упорядочить по tranid и фильтром отобрать строки в кадре с крайней нижней (UNBOUNDED PRECEDING) до текущей. Вот соответствующий запрос:
SELECT actid, tranid, val, SUM(val) OVER(PARTITION BY actid ORDER BY tranid ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS balance FROM dbo.Transactions;
Этот код не только простой и прямолинейный - он и выполняется быстро. План этого запроса показан на рисунке:
В таблице есть кластеризованный индекс, который отвечает требованиям POC и пригоден для использования оконными функциями. В частности, список ключей индекса основан на элементе секционирования (actid), за которым следует элемент упорядочения (tranid), также для обеспечения покрытия индекс включает все остальные столбцы в запросе (val). План содержит упорядоченный просмотр, за которым следует вычисление номера строки для внутренних нужд, а затем - оконного агрегата. Так как есть POC-индекс, оптимизатору не нужно добавлять в план оператор сортировки. Это очень эффективный план. К тому же он линейно масштабируется. Позже, когда я покажу результаты сравнения производительности, вы увидите, насколько эффективнее этот способ по сравнению со старыми решениями.
До SQL Server 2012 использовались либо вложенные запросы, либо соединения. При использовании вложенного запроса нарастающие итоги вычисляются путем фильтрации всех строк с тем же значением actid, что и во внешней строке, и значением tranid, которое меньше или равно значения во внешней строке. Затем к отфильтрованным строкам применяется агрегирование. Вот соответствующий запрос:
Аналогичный подход можно реализовать с применением соединений. Используется тот же предикат, что и в предложении WHERE вложенного запроса в предложении ON соединения. В этом случае для N-ой транзакции одного и того же счета A в экземпляре, обозначенном как T1, вы будете находить N соответствий в экземпляре T2, при этом номера транзакций пробегают от 1 до N. В результате сопоставления строки в T1 повторяются, поэтому нужно сгруппировать строки по всем элементам с T1, чтобы получить информацию о текущей транзакции и применить агрегирование к атрибуту val из T2 для вычисления нарастающего итога. Готовый запрос выглядит примерно так:
SELECT T1.actid, T1.tranid, T1.val, SUM(T2.val) AS balance FROM dbo.Transactions AS T1 JOIN dbo.Transactions AS T2 ON T2.actid = T1.actid AND T2.tranid <= T1.tranid GROUP BY T1.actid, T1.tranid, T1.val;
На рисунке ниже приведены планы обоих решений:

Заметьте, что в обоих случаях в экземпляре T1 выполняется полный просмотр кластеризованного индекса. Затем для каждой строки в плане предусмотрена операция поиска в индексе начала раздела текущего счета на конечной странице индекса, при этом считываются все транзакции, в которых T2.tranid меньше или равно T1.tranid. Точка, где происходит агрегирование строк, немного отличается в планах, но число считанных строк одинаково.
Чтобы понять, сколько строк просматривается, надо учесть число элементов данных. Пусть p - число секций (счетов), а r - число строк в секции (транзакции). Тогда число строк в таблице примерно равно p*r, если считать, что транзакции распределены по счетам равномерно. Таким образом, приведенный в верхней части просмотр охватывает p*r строк. Но больше всего нас интересует происходящее в итераторе Nested Loops.
В каждой секции план предусматривает чтение 1 + 2 + ... + r строк, что в сумме составляет (r + r*2) / 2. Общее количество обрабатываемых в планах строк составляет p*r + p*(r + r2) / 2. Это означает, что число операций в плане растет в квадрате с увеличением размера секции, то есть если увеличить размер секции в f раз, объем работы увеличится примерно в f 2 раз. Это плохо. Для примера 100 строкам соответствует 10 тыс. строк, а тысяче строк соответствует миллион и т.д. Проще говоря это приводит к сильному замедлению выполнения запросов при немаленьком размере секции, потому что квадратичная функция растет очень быстро. Подобные решения работают удовлетворительно при нескольких десятках строк на секцию, но не больше.
Решения с использованием курсора
Решения на основе курсора реализуются «в лоб». Объявляется курсор на основе запроса, упорядочивающего данные по actid и tranid. После этого выполняется итеративный проход записей курсора. При обнаружении нового счета сбрасывается переменная, содержащая агрегат. В каждой итерации в переменную добавляется сумма новой транзакции, после этого строка сохраняется в табличной переменной с информацией о текущей транзакции плюс текущее значение нарастающего итога. После итеративного прохода возвращается результат из табличной переменной. Вот код законченного решения:
DECLARE @Result AS TABLE (actid INT, tranid INT, val MONEY, balance MONEY); DECLARE @actid AS INT, @prvactid AS INT, @tranid AS INT, @val AS MONEY, @balance AS MONEY; DECLARE C CURSOR FAST_FORWARD FOR SELECT actid, tranid, val FROM dbo.Transactions ORDER BY actid, tranid; OPEN C FETCH NEXT FROM C INTO @actid, @tranid, @val; SELECT @prvactid = @actid, @balance = 0; WHILE @@fetch_status = 0 BEGIN IF @actid <> @prvactid SELECT @prvactid = @actid, @balance = 0; SET @balance = @balance + @val; INSERT INTO @Result VALUES(@actid, @tranid, @val, @balance); FETCH NEXT FROM C INTO @actid, @tranid, @val; END CLOSE C; DEALLOCATE C; SELECT * FROM @Result;
План запроса с использованием курсора показан на рисунке:

Этот план масштабируется линейно, потому что данные из индекса просматриваются только раз в определенном порядке. Также у каждой операции получения строки из курсора примерно одинаковая стоимость в расчете на каждую строку. Если принять нагрузку, создаваемую при обработке одной строки курсора, равной g, стоимость этого решения можно оценить как p*r + p*r*g (как вы помните, p - это число секций, а r - число строк в секции). Так что, если увеличить число строк на секцию в f раз, нагрузка на систему составит p*r*f + p*r*f*g, то есть будет расти линейно. Стоимость обработки в расчете на строку высока, но из-за линейного характера масштабирования, с определенного размера секции это решение будет демонстрировать лучшую масштабируемость, чем решения на основе вложенных запросов и соединений из-за квадратичного масштабирования этих решений. Проведенное мной измерение производительности показало, что число, когда решение с курсором работает быстрее, равно нескольким сотням строк на секцию.
Несмотря на выигрыш в производительности, обеспечиваемый решениями на основе курсора, в общем случае их надо избегать, потому что они не являются реляционными.
Решения на основе CLR
Одно возможное решение на основе CLR (Common Language Runtime) по сути является одной из форм решения с использованием курсора. Разница в том, что вместо использования курсора T-SQL, который тратит много ресурсов на получение очередной строки и выполнение итерации, применяются итерации.NET SQLDataReader и.NET, которые работают намного быстрее. Одна из особенностей CLR которая делает этот вариант быстрее, заключается в том, что результирующая строка во временной таблице не нужна - результаты пересылаются напрямую вызывающему процессу. Логика решения на основе CLR похожа на логику решения с использованием курсора и T-SQL. Вот код C#, определяющий хранимую процедуру решения:
Using System; using System.Data; using System.Data.SqlClient; using System.Data.SqlTypes; using Microsoft.SqlServer.Server; public partial class StoredProcedures { public static void AccountBalances() { using (SqlConnection conn = new SqlConnection("context connection=true;")) { SqlCommand comm = new SqlCommand(); comm.Connection = conn; comm.CommandText = @"" + "SELECT actid, tranid, val " + "FROM dbo.Transactions " + "ORDER BY actid, tranid;"; SqlMetaData columns = new SqlMetaData; columns = new SqlMetaData("actid" , SqlDbType.Int); columns = new SqlMetaData("tranid" , SqlDbType.Int); columns = new SqlMetaData("val" , SqlDbType.Money); columns = new SqlMetaData("balance", SqlDbType.Money); SqlDataRecord record = new SqlDataRecord(columns); SqlContext.Pipe.SendResultsStart(record); conn.Open(); SqlDataReader reader = comm.ExecuteReader(); SqlInt32 prvactid = 0; SqlMoney balance = 0; while (reader.Read()) { SqlInt32 actid = reader.GetSqlInt32(0); SqlMoney val = reader.GetSqlMoney(2); if (actid == prvactid) { balance += val; } else { balance = val; } prvactid = actid; record.SetSqlInt32(0, reader.GetSqlInt32(0)); record.SetSqlInt32(1, reader.GetSqlInt32(1)); record.SetSqlMoney(2, val); record.SetSqlMoney(3, balance); SqlContext.Pipe.SendResultsRow(record); } SqlContext.Pipe.SendResultsEnd(); } } }
Чтобы иметь возможность выполнить эту хранимую процедуру в SQL Server, сначала надо на основе этого кода построить сборку по имени AccountBalances и развернуть в базе данных TSQL2012. Если вы не знакомы с развертыванием сборок в SQL Server, можете почитать раздел «Хранимые процедуры и среда CLR» в статье «Хранимые процедуры» .
Если вы назвали сборку AccountBalances, а путь к файлу сборки - "C:\Projects\AccountBalances\bin\Debug\AccountBalances.dll", загрузить сборку в базу данных и зарегистрировать хранимую процедуру можно следующим кодом:
CREATE ASSEMBLY AccountBalances FROM "C:\Projects\AccountBalances\bin\Debug\AccountBalances.dll"; GO CREATE PROCEDURE dbo.AccountBalances AS EXTERNAL NAME AccountBalances.StoredProcedures.AccountBalances;
После развертывания сборки и регистрации процедуры можно ее выполнить следующим кодом:
EXEC dbo.AccountBalances;
Как я уже говорил, SQLDataReader является всего лишь еще одной формой курсора, но в этой версии затраты на чтение строк значительно меньше, чем при использовании традиционного курсора в T-SQL. Также в.NET итерации выполняются намного быстрее, чем в T-SQL. Таким образом, решения на основе CLR тоже масштабируются линейно. Тестирование показало, что производительность этого решения становится выше производительности решений с использованием подзапросов и соединений, когда число строк в секции переваливает через 15.
По завершении надо выполнить следующий код очистки:
DROP PROCEDURE dbo.AccountBalances; DROP ASSEMBLY AccountBalances;
Вложенные итерации
До этого момента я показывал итеративные решения и решения на основе наборов. Следующее решение основано на вложенных итерациях, которые являются гибридом итеративного и основанного на наборах подходов. Идея заключается в том, чтобы предварительно скопировать строки из таблицы-источника (в нашем случае это банковские счета) во временную таблицу вместе с новым атрибутом по имени rownum, который вычисляется с использованием функции ROW_NUMBER. Номера строк секционируются по actid и упорядочиваются по tranid, поэтому первой транзакции в каждом банковском счете назначается номер 1, второй транзакции - 2 и т.д. Затем во временной таблице создается кластеризованный индекс со списком ключей (rownum, actid). Затем используется рекурсивное выражение CTE или специально созданный цикл для обработки по одной строке за итерацию во всех счетах. Затем нарастающий итог вычисляется путем суммирования значения, соответствующего текущей строке, со значением, связанным с предыдущей строкой. Вот реализация этой логики с использованием рекурсивного CTE:
SELECT actid, tranid, val, ROW_NUMBER() OVER(PARTITION BY actid ORDER BY tranid) AS rownum INTO #Transactions FROM dbo.Transactions; CREATE UNIQUE CLUSTERED INDEX idx_rownum_actid ON #Transactions(rownum, actid); WITH C AS (SELECT 1 AS rownum, actid, tranid, val, val AS sumqty FROM #Transactions WHERE rownum = 1 UNION ALL SELECT PRV.rownum + 1, PRV.actid, CUR.tranid, CUR.val, PRV.sumqty + CUR.val FROM C AS PRV JOIN #Transactions AS CUR ON CUR.rownum = PRV.rownum + 1 AND CUR.actid = PRV.actid) SELECT actid, tranid, val, sumqty FROM C OPTION (MAXRECURSION 0); DROP TABLE #Transactions;
А это реализация с использованием явного цикла:
SELECT ROW_NUMBER() OVER(PARTITION BY actid ORDER BY tranid) AS rownum, actid, tranid, val, CAST(val AS BIGINT) AS sumqty INTO #Transactions FROM dbo.Transactions; CREATE UNIQUE CLUSTERED INDEX idx_rownum_actid ON #Transactions(rownum, actid); DECLARE @rownum AS INT; SET @rownum = 1; WHILE 1 = 1 BEGIN SET @rownum = @rownum + 1; UPDATE CUR SET sumqty = PRV.sumqty + CUR.val FROM #Transactions AS CUR JOIN #Transactions AS PRV ON CUR.rownum = @rownum AND PRV.rownum = @rownum - 1 AND CUR.actid = PRV.actid; IF @@rowcount = 0 BREAK; END SELECT actid, tranid, val, sumqty FROM #Transactions; DROP TABLE #Transactions;
Это решение обеспечивает хорошую производительность, когда есть большое число секций с небольшим числом строк в секциях. Тогда число итераций небольшое, а основная работа выполняется основанной на наборах частью решения, которая соединяет строки, связанные с одним номером строки, со строками, связанными с предыдущим номером строки.
Многострочное обновление с переменными
Показанные до этого момента приемы вычисления нарастающих итогов гарантированно дают правильный результат. Описываемая в этом разделе методика неоднозначна, потому что основана на наблюдаемом, а не задокументированном поведении системы, кроме того она противоречит принципам релятивности. Высокая ее привлекательность обусловлена большой скоростью работы.
В этом способе используется инструкция UPDATE с переменными. Инструкция UPDATE может присваивать переменным выражения на основе значения столбца, а также присваивать значениям в столбцах выражение с переменной. Решение начинается с создания временной таблицы по имени Transactions с атрибутами actid, tranid, val и balance и кластеризованного индекса со списком ключей (actid, tranid). Затем временная таблица наполняется всеми строками из исходной БД Transactions, причем в столбец balance всех строк вводится значение 0,00. Затем вызывается инструкция UPDATE с переменными, связанными с временной таблицей, для вычисления нарастающих итогов и вставки вычисленного значения в столбец balance.
Используются переменные @prevaccount и @prevbalance, а значение в столбце balance вычисляется с применением следующего выражения:
SET @prevbalance = balance = CASE WHEN actid = @prevaccount THEN @prevbalance + val ELSE val END
Выражение CASE проверяет, не совпадают ли идентификаторы текущего и предыдущего счетов, и, если они равны, возвращает сумму предыдущего и текущего значений в столбце balance. Если идентификаторы счетов разные, возвращается сумма текущей транзакции. Далее результат выражения CASE вставляется в столбец balance и присваивается переменной @prevbalance. В отдельном выражении переменной ©prevaccount присваивается идентификатор текущего счета.
После выражения UPDATE решение представляет строки из временной таблицы и удаляет последнюю. Вот код законченного решения:
CREATE TABLE #Transactions (actid INT, tranid INT, val MONEY, balance MONEY); CREATE CLUSTERED INDEX idx_actid_tranid ON #Transactions(actid, tranid); INSERT INTO #Transactions WITH (TABLOCK) (actid, tranid, val, balance) SELECT actid, tranid, val, 0.00 FROM dbo.Transactions ORDER BY actid, tranid; DECLARE @prevaccount AS INT, @prevbalance AS MONEY; UPDATE #Transactions SET @prevbalance = balance = CASE WHEN actid = @prevaccount THEN @prevbalance + val ELSE val END, @prevaccount = actid FROM #Transactions WITH(INDEX(1), TABLOCKX) OPTION (MAXDOP 1); SELECT * FROM #Transactions; DROP TABLE #Transactions;
План этого решения показан на следующем рисунке. Первая часть представлена инструкцией INSERT, вторая - UPDATE, а третья - SELECT:

В этом решении предполагается, что при оптимизации выполнения UPDATE всегда будет выполняться упорядоченный просмотр кластеризованного индекса, и в решении предусмотрен ряд подсказок, чтобы предотвратить обстоятельства, которые могут помешать этому, например параллелизм. Проблема в том, что нет никакой официальной гарантии, что оптимизатор всегда будет посматривать в порядке кластеризованного индекса. Нельзя полагаться на особенности физических вычислений, когда нужно обеспечить логическую корректность кода, если только в коде нет логических элементов, которые по определению могут гарантировать такое поведение. В данном коде нет никаких логических особенностей, которые могли бы гарантировать именно такое поведение. Естественно выбор, использовать или нет этот способ, лежит целиком на вашей совести. Я считаю, что безответственно использовать его, даже если вы тысячи раз проверяли и «вроде бы все работает, как надо».
К счастью, в SQL Server 2012 этот выбор становится практически ненужным. При наличии исключительно эффективного решения с использованием оконных функций агрегирования не приходится задумываться о других решениях.
Измерение производительности
Я провел измерение и сравнение производительности различных методик. Результаты приведены на рисунках ниже:

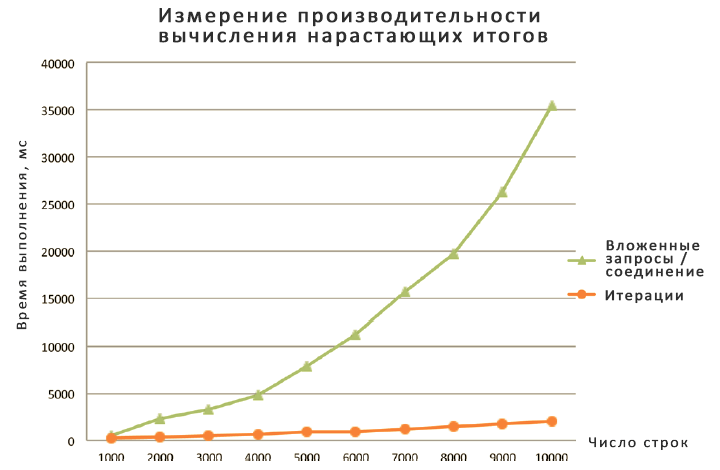
Я разбил результаты на два графика из-за того, что способ с использованием вложенного запроса или соединения настолько медленнее остальных, что мне пришлось использовать для него другой масштаб. В любом случае, обратите внимание, что большинство решений демонстрируют линейную зависимость объема работы от размера секции, и только решение на основе вложенного запроса или соединения показывают квадратичную зависимость. Также ясно видно, насколько эффективнее новое решение на основе оконной функции агрегирования. Решение на основе UPDATE с переменными тоже очень быстрое, но по описанным уже причинам я не рекомендую его использовать. Решение с использованием CLR также вполне быстрое, но в нем нужно писать весь этот код.NET и разворачивать сборку в базе данных. Как ни посмотри, а основанное на наборах решение с использованием оконных агрегатов остается самым предпочтительным.
Описывается использование арифметических операторов и построение вычисляемых столбцов. Рассматриваются итоговые (агрегатные) функции COUNT, SUM, AVG, MAX, MIN. Дается пример использования оператора GROUP BY для группировки в запросах выборки данных. Описывается применение предложения HAVING.Построение вычисляемых полей
В общем случае для создания вычисляемого (производного) поля в списке SELECT следует указать некоторое выражение языка SQL. В этих выражениях применяются арифметические операции сложения, вычитания, умножения и деления, а также встроенные функции языка SQL. Можно указать имя любого столбца (поля) таблицы или запроса, но использовать имя столбца только той таблицы или запроса, которые указаны в списке предложения FROM соответствующей инструкции. При построении сложных выражений могут понадобиться скобки.
Стандарты SQL позволяют явным образом задавать имена столбцов результирующей таблицы, для чего применяется фраза AS .
SELECT Товар.Название, Товар.Цена, Сделка.Количество, Товар.Цена*Сделка.Количество AS Стоимость FROM Товар INNER JOIN Сделка ON Товар.КодТовара=Сделка.КодТовара Пример 6.1. Рассчет общей стоимости для каждой сделки.
Пример 6.2. Получить список фирм с указанием фамилии и инициалов клиентов.
SELECT Фирма, Фамилия+""+ Left(Имя,1)+"."+Left(Отчество,1)+"."AS ФИО FROM Клиент Пример 6.2. Получение списка фирм с указанием фамилии и инициалов клиентов.
В запросе использована встроенная функция Left , позволяющая вырезать в текстовой переменной один символ слева в данном случае.
Пример 6.3. Получить список товаров с указанием года и месяца продажи.
SELECT Товар.Название, Year(Сделка.Дата) AS Год, Month(Сделка.Дата) AS Месяц FROM Товар INNER JOIN Сделка ON Товар.КодТовара=Сделка.КодТовара Пример 6.3. Получение списка товаров с указанием года и месяца продажи.
В запросе использованы встроенные функции Year и Month для выделения года и месяца из даты.
Использование итоговых функций
С помощью итоговых (агрегатных) функций в рамках SQL-запроса можно получить ряд обобщающих статистических сведений о множестве отобранных значений выходного набора.
Пользователю доступны следующие основные итоговые функции :
- Count (Выражение) - определяет количество записей в выходном наборе SQL-запроса;
- Min/Max (Выражение) - определяют наименьшее и наибольшее из множества значений в некотором поле запроса;
- Avg (Выражение) - эта функция позволяет рассчитать среднее значение множества значений, хранящихся в определенном поле отобранных запросом записей. Оно является арифметическим средним значением, т.е. суммой значений, деленной на их количество.
- Sum (Выражение) - вычисляет сумму множества значений, содержащихся в определенном поле отобранных запросом записей.
Чаще всего в качестве выражения выступают имена столбцов. Выражение может вычисляться и по значениям нескольких таблиц.
Все эти функции оперируют со значениями в единственном столбце таблицы или с арифметическим выражением и возвращают единственное значение. Функции COUNT , MIN и MAX применимы как к числовым, так и к нечисловым полям, тогда как функции SUM и AVG могут использоваться только в случае числовых полей, за исключением COUNT(*) . При вычислении результатов любых функций сначала исключаются все пустые значения, после чего требуемая операция применяется только к оставшимся конкретным значениям столбца. Вариант COUNT(*) - особый случай использования функции COUNT , его назначение состоит в подсчете всех строк в результирующей таблице, независимо от того, содержатся там пустые, дублирующиеся или любые другие значения.
Если до применения обобщающей функции необходимо исключить дублирующиеся значения, следует перед именем столбца в определении функции поместить ключевое слово DISTINCT . Оно не имеет смысла для функций MIN и MAX , однако его использование может повлиять на результаты выполнения функций SUM и AVG , поэтому необходимо заранее обдумать, должно ли оно присутствовать в каждом конкретном случае. Кроме того, ключевое слово DISTINCT может быть указано в любом запросе не более одного раза.
Очень важно отметить, что итоговые функции могут использоваться только в списке предложения SELECT и в составе предложения HAVING . Во всех других случаях это недопустимо. Если список в предложении SELECT содержит итоговые функции , а в тексте запроса отсутствует фраза GROUP BY , обеспечивающая объединение данных в группы, то ни один из элементов списка предложения SELECT не может включать каких-либо ссылок на поля, за исключением ситуации, когда поля выступают в качестве аргументов итоговых функций .
Пример 6.4. Определить первое по алфавиту название товара.
SELECT Min(Товар.Название) AS Min_Название FROM Товар Пример 6.4. Определение первого по алфавиту названия товара.
Пример 6.5. Определить количество сделок.
SELECT Count(*) AS Количество_сделок FROM Сделка Пример 6.5. Определить количество сделок.
Пример 6.6. Определить суммарное количество проданного товара.
SELECT Sum(Сделка.Количество) AS Количество_товара FROM Сделка Пример 6.6. Определение суммарного количества проданного товара.
Пример 6.7. Определить среднюю цену проданного товара.
SELECT Avg(Товар.Цена) AS Avg_Цена FROM Товар INNER JOIN Сделка ON Товар.КодТовара=Сделка.КодТовара; Пример 6.7. Определение средней цены проданного товара.
SELECT Sum(Товар.Цена*Сделка.Количество) AS Стоимость FROM Товар INNER JOIN Сделка ON Товар.КодТовара=Сделка.КодТовара Пример 6.8. Подсчет общей стоимости проданных товаров.
Предложение GROUP BY
Часто в запросах требуется формировать промежуточные итоги, что обычно отображается появлением в запросе фразы "для каждого...". Для этой цели в операторе SELECT используется предложение GROUP BY . Запрос, в котором присутствует GROUP BY , называется группирующим запросом, поскольку в нем группируются данные, полученные в результате выполнения операции SELECT , после чего для каждой отдельной группы создается единственная суммарная строка. Стандарт SQL требует, чтобы предложение SELECT и фраза GROUP BY были тесно связаны между собой. При наличии в операторе SELECT фразы GROUP BY каждый элемент списка в предложении SELECT должен иметь единственное значение для всей группы. Более того, предложение SELECT может включать только следующие типы элементов: имена полей, итоговые функции , константы и выражения, включающие комбинации перечисленных выше элементов.
Все имена полей, приведенные в списке предложения SELECT , должны присутствовать и во фразе GROUP BY - за исключением случаев, когда имя столбца используется в итоговой функции . Обратное правило не является справедливым - во фразе GROUP BY могут быть имена столбцов, отсутствующие в списке предложения SELECT .
Если совместно с GROUP BY используется предложение WHERE , то оно обрабатывается первым, а группированию подвергаются только те строки, которые удовлетворяют условию поиска.
Стандартом SQL определено, что при проведении группирования все отсутствующие значения рассматриваются как равные. Если две строки таблицы в одном и том же группируемом столбце содержат значение NULL и идентичные значения во всех остальных непустых группируемых столбцах, они помещаются в одну и ту же группу.
Пример 6.9. Вычислить средний объем покупок, совершенных каждым покупателем.
SELECT Клиент.Фамилия, Avg(Сделка.Количество) AS Среднее_количество FROM Клиент INNER JOIN Сделка ON Клиент.КодКлиента=Сделка.КодКлиента GROUP BY Клиент.Фамилия Пример 6.9. Вычисление среднего объема покупок, совершенных каждым покупателем.
Фраза "каждым покупателем" нашла свое отражение в SQL-запросе в виде предложения GROUP BY Клиент.Фамилия .
Пример 6.10. Определить, на какую сумму был продан товар каждого наименования.
SELECT Товар.Название, Sum(Товар.Цена*Сделка.Количество) AS Стоимость FROM Товар INNER JOIN Сделка ON Товар.КодТовара=Сделка.КодТовара GROUP BY Товар.Название Пример 6.10. Определение, на какую сумму был продан товар каждого наименования.
SELECT Клиент.Фирма, Count(Сделка.КодСделки) AS Количество_сделок FROM Клиент INNER JOIN Сделка ON Клиент.КодКлиента=Сделка.КодКлиента GROUP BY Клиент.Фирма Пример 6.11. Подсчет количества сделок, осуществленных каждой фирмой.
SELECT Клиент.Фирма, Sum(Сделка.Количество) AS Общее_Количество, Sum(Товар.Цена*Сделка.Количество) AS Стоимость FROM Товар INNER JOIN (Клиент INNER JOIN Сделка ON Клиент.КодКлиента=Сделка.КодКлиента) ON Товар.КодТовара=Сделка.КодТовара GROUP BY Клиент.Фирма Пример 6.12. Подсчет общего количества купленного для каждой фирмы товара и его стоимости.
Пример 6.13. Определить суммарную стоимость каждого товара за каждый месяц.
SELECT Товар.Название, Month(Сделка.Дата) AS Месяц, Sum(Товар.Цена*Сделка.Количество) AS Стоимость FROM Товар INNER JOIN Сделка ON Товар.КодТовара=Сделка.КодТовара GROUP BY Товар.Название, Month(Сделка.Дата) Пример 6.13. Определение суммарной стоимости каждого товара за каждый месяц.
Пример 6.14. Определить суммарную стоимость каждого товара первого сорта за каждый месяц.
SELECT Товар.Название, Month(Сделка.Дата) AS Месяц, Sum(Товар.Цена*Сделка.Количество) AS Стоимость FROM Товар INNER JOIN Сделка ON Товар.КодТовара=Сделка.КодТовара WHERE Товар.Сорт="Первый" GROUP BY Товар.Название, Month(Сделка.Дата) Пример 6.14. Определение суммарной стоимости каждого товара первого сорта за каждый месяц.
Предложение HAVING
При помощи HAVING отражаются все предварительно сгруппированные посредством GROUP BY блоки данных, удовлетворяющие заданным в HAVING условиям. Это дополнительная возможность "профильтровать" выходной набор.
Условия в HAVING отличаются от условий в WHERE :
- HAVING исключает из результирующего набора данных группы с результатами агрегированных значений;
- WHERE исключает из расчета агрегатных значений по группировке записи, не удовлетворяющие условию;
- в условии поиска WHERE нельзя задавать агрегатные функции.
Пример 6.15. Определить фирмы, у которых общее количество сделок превысило три.
SELECT Клиент.Фирма, Count(Сделка.Количество) AS Количество_сделок FROM Клиент INNER JOIN Сделка ON Клиент.КодКлиента=Сделка.КодКлиента GROUP BY Клиент.Фирма HAVING Count(Сделка.Количество)>3 Пример 6.15. Определение фирм, у которых общее количество сделок превысило три.
Пример 6.16. Вывести список товаров, проданных на сумму более 10000 руб.
SELECT Товар.Название, Sum(Товар.Цена*Сделка.Количество) AS Стоимость FROM Товар INNER JOIN Сделка ON Товар.КодТовара=Сделка.КодТовара GROUP BY Товар.Название HAVING Sum(Товар.Цена*Сделка.Количество)>10000 Пример 6.16. Вывод списка товаров, проданных на сумму более 10000 руб.
Пример 6.17. Вывести список товаров, проданных на сумму более 10000 без указания суммы.
SELECT Товар.Название FROM Товар INNER JOIN Сделка ON Товар.КодТовара=Сделка.КодТовара GROUP BY Товар.Название HAVING Sum(Товар.Цена*Сделка.Количество)>10000 Пример 6.17. Вывод списка товаров, проданных на сумму более 10000 без указания суммы.
Предыдущая статья: Как получить голоса вконтакте Следующая статья: VKMix (ВКМикс) – накрутка лайков, подписчиков, репостов в ВКонтакте, Инстаграм, Ютуб